Today I'm going to hack deep into the open source jungle to search for examples of wild repository. We'll be able to see the way that this species mutated into many divergent forms, and maybe learn some lessons about growing our own domestic repository on the way.
There's a lot of discussion about what a repository should be. I'm just going to be looking at generic repositories in this post, but it's worth noting that many people have the opinion that such a thing should not be blessed with the name repository; saying that it is merely a generic DAO. I'll leave these semantic arguments for another day.
As I was finishing this post, I came upon DDD Repositories in the wild: Colin Jack by Tobin Harris. It just goes to show that I don't have a single original idea :P
Rhino Commons
I first heard tell of the generic repository in this excellent article by Ayende (AKA Oren Eini) on Inversion of Control containers. So it's only fair that I start with Ayende's own IRepository<T> from Rhino.Commons. It's worth noting that this particular example is now extinct, Ayende now believes that you should tailor a specific IRepository<T> per project.

Wow, it's huge! This kind of gigantism can occur in any class if left untended by the SRP. Ayende is heroically scathing of his own creation:
"To take the IRepository<T> example, it currently have over 50 methods. If that isn't a violation of SRP, I don't know what is. Hell, you can even execute a stored procedure using the IRepository<T> infrastructure. That is too much."
It's also worth noting that this repository exposes NHibernate types such as DetachedCriteria and ICriterion. You couldn't use it with any other ORM. I also dislike the paging and ordering concerns that have leaked into the FindAll methods.
A last point worth noting is that all the methods that return collections return an ICollection<T>.
Sharp Architecture
Next we encounter the Sharp Architecture repository:
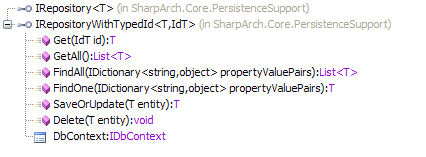
A nice small repository with close to the minimum number of methods you could get away with. Billy McCafferty has had to work hard to keep it this way, coming under some pressure to let it bloat. It's somewhat limited in the kind of filtering you can do with the FindAll and FindOne methods as they are limited to filtering on property values. Sharp architecture is also based around NHibernate, but no NHibernate types have been allowed to find their way into the repository.
Notice that IRepository is a specialisation of IRepositoryWithTypeId. This is a useful generalisation for situations where your primary keys are types other than int.
The collection type of choice here is List<T>.
Fluent NHibernate
Wandering deeper into the forest we run headfirst into Fluent NHibernate. They provide another pleasantly small repository implementation:
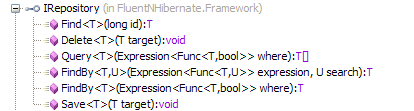
This one is interesting because it's the first time we've seen any use of System.Linq in a repository. The Query method and both the FindBy overloads take a LINQ expression. Looking at their NHibernate implementation one can see that this is simply passed through to the NHibernate.Linq provider. The collection type used is a simple array, so although a LINQ provider is used to resolve the collection from the given expression, they don't want to make sure that the expression has been executed and the final collection created before it leaves the repository.
Primary keys are expected to be long values, which is useful when you've got more than two billion records :)
Suteki Shop
Last, and most definitely least, I'd like to show you my own domesticated repository from Suteki Shop:
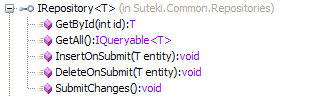
The most controversial aspect is that I return IQueryable<T> from my GetAll method. You can read my attempt at justifying this here. Another point of difference is that I surface the underlying unit of work. Nothing is persisted to the database until the client calls SubmitChanges. Most other repositories hide this behind a simpler 'Save' or 'SaveOrUpdate' method. I don't really have a strong opinion about this, so I could probably be persuaded that the simpler approach is best.
So?
So, leaving the Rhino Commons monster aside, the main difference between the other three repositories is the way the find or query methods are structured. LINQ is the battleground: Do you keep well away, like Sharp Architecture? Do you leverage expressions, but make sure the collection is loaded by the time it leaves the repository? Or do you run with scissors and return IQueryable<T>?
Allowing types from System.Linq to be exposed from the repository is OK because it's a core part of the .NET framework, but what about NHibernate types like ICriteria? I think it's a poor choice to surface these. We should be attempting to insulate the application from the data access tools. In theory we should be able to swap in any reasonably well specified ORM. In practice I've found this to be problematic because of the different mapping and LINQ capabilities provided by different ORMs, but the intention should remain.
Just to wind up, I'd be very interested in hearing about other generic repository implementations out there. I'm going to be giving a talk next week about this pattern and need lots of help!