
Today I'm going to hack deep into the open source jungle to search for examples of wild repository. We'll be able to see the way that this species mutated into many divergent forms, and maybe learn some lessons about growing our own domestic repository on the way.
There's a lot of discussion about what a repository should be. I'm just going to be looking at generic repositories in this post, but it's worth noting that many people have the opinion that such a thing should not be blessed with the name repository; saying that it is merely a generic DAO. I'll leave these semantic arguments for another day.
As I was finishing this post, I came upon DDD Repositories in the wild: Colin Jack by Tobin Harris. It just goes to show that I don't have a single original idea :P
Rhino Commons
I first heard tell of the generic repository in this excellent article by Ayende (AKA Oren Eini) on Inversion of Control containers. So it's only fair that I start with Ayende's own IRepository<T> from Rhino.Commons. It's worth noting that this particular example is now extinct, Ayende now believes that you should tailor a specific IRepository<T> per project.

Wow, it's huge! This kind of gigantism can occur in any class if left untended by the SRP. Ayende is heroically scathing of his own creation:
"To take the IRepository<T> example, it currently have over 50 methods. If that isn't a violation of SRP, I don't know what is. Hell, you can even execute a stored procedure using the IRepository<T> infrastructure. That is too much."
It's also worth noting that this repository exposes NHibernate types such as DetachedCriteria and ICriterion. You couldn't use it with any other ORM. I also dislike the paging and ordering concerns that have leaked into the FindAll methods.
A last point worth noting is that all the methods that return collections return an ICollection<T>.
Sharp Architecture
Next we encounter the Sharp Architecture repository:
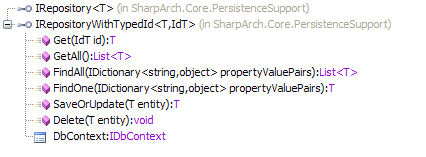
A nice small repository with close to the minimum number of methods you could get away with. Billy McCafferty has had to work hard to keep it this way, coming under some pressure to let it bloat. It's somewhat limited in the kind of filtering you can do with the FindAll and FindOne methods as they are limited to filtering on property values. Sharp architecture is also based around NHibernate, but no NHibernate types have been allowed to find their way into the repository.
Notice that IRepository is a specialisation of IRepositoryWithTypeId. This is a useful generalisation for situations where your primary keys are types other than int.
The collection type of choice here is List<T>.
Fluent NHibernate
Wandering deeper into the forest we run headfirst into Fluent NHibernate. They provide another pleasantly small repository implementation:
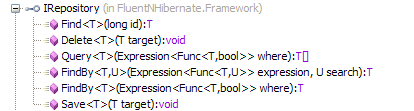
This one is interesting because it's the first time we've seen any use of System.Linq in a repository. The Query method and both the FindBy overloads take a LINQ expression. Looking at their NHibernate implementation one can see that this is simply passed through to the NHibernate.Linq provider. The collection type used is a simple array, so although a LINQ provider is used to resolve the collection from the given expression, they don't want to make sure that the expression has been executed and the final collection created before it leaves the repository.
Primary keys are expected to be long values, which is useful when you've got more than two billion records :)
Suteki Shop
Last, and most definitely least, I'd like to show you my own domesticated repository from Suteki Shop:
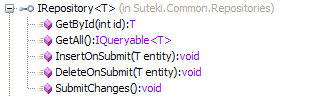
The most controversial aspect is that I return IQueryable<T> from my GetAll method. You can read my attempt at justifying this here. Another point of difference is that I surface the underlying unit of work. Nothing is persisted to the database until the client calls SubmitChanges. Most other repositories hide this behind a simpler 'Save' or 'SaveOrUpdate' method. I don't really have a strong opinion about this, so I could probably be persuaded that the simpler approach is best.
So?
So, leaving the Rhino Commons monster aside, the main difference between the other three repositories is the way the find or query methods are structured. LINQ is the battleground: Do you keep well away, like Sharp Architecture? Do you leverage expressions, but make sure the collection is loaded by the time it leaves the repository? Or do you run with scissors and return IQueryable<T>?
Allowing types from System.Linq to be exposed from the repository is OK because it's a core part of the .NET framework, but what about NHibernate types like ICriteria? I think it's a poor choice to surface these. We should be attempting to insulate the application from the data access tools. In theory we should be able to swap in any reasonably well specified ORM. In practice I've found this to be problematic because of the different mapping and LINQ capabilities provided by different ORMs, but the intention should remain.
Just to wind up, I'd be very interested in hearing about other generic repository implementations out there. I'm going to be giving a talk next week about this pattern and need lots of help!


12 comments:
Good luck in your quest!
We've had several arguments as to whether Repositories should :
- Publicly depend on a persistence framework such as NHibernate
- Whether encapsulating Queries into Query objects (which have quickly to be unwrapped into the specific technology support by the persistence framework) is hiding a dependency that is not anyway easy to get rid off
- Have methods like Save, Delete that perform transaction commits
- Similar the point just before, whether Repositories should perform any kind of direct control of transaction boundaries (BeginTransaction, Commit)
- Whether we can get away with a single IRepository and use Extension methods when that needs extending or maybe it's best to use a Repository per aggregate roots when trying DDD
- Whether saying you can "Delete" on something that shouldn't be deletable is a good thing ?
I firmly believe there is a lot of confusion about Repositories in that a lot of times for small scale projects they just really are DAO objects really. I am not sure if the term Repository comes from DDD but if it does there are quite a few rules that need applying there.
PS: I saw a Wild repository, it was black and huge but I couldn't see because there was a lot of fog. Is that it ?
Daniel
Hi Mike,
Of the repositories you discuss, I like your's best. I'm not sucking up though because I think it has a flaw! ;)
For me, a repository should be pretty low-level, it should not make decisions about transactions, but it should take part in them. I agree with exposing IQueryable since this is exactly the kind of thing it is intended for. However, that does mean we have to understand a little about the underlying persistence mechanism. Guess what: if you don't understand your persistence mechanism you'll end up making bad decisions at some point anyway.
So let's review your repository:
- Lightweight: check.
- Transaction ignorant: (can't tell from the interface really but I know that it is 'cause I've looked at the Suteki code) check.
- Allows LINQ queries (and therefore easily composable filters): check.
So here's what I think's wrong with it. If you need to load two entities, each from a different repository type (in order to create a relationship between them for example): on which entity's repository should I call the SubmitChanges method?
In reality, it makes no difference (with LINQ to SQL) because the first call does a save, and the second one does nothing. However, I like the idea of a 'Save(T entity)' method and 'IDataContext DataContext { get; }' property on IRepository. This way, each repository is explicitly associated with a specific unit of work which can be the go-to-place for the SubmitChanges method. The SubmitChanges method then because the obvious place to put transaction handling (if there isn't an ambient one). The downside here is that now we're almost entirely mirroring the LINQ to SQL architecture where there is a bunch of tables coming from a DC. Is that a bad thing?
TTFN,
Damian.
Hi Mike
As I've mentioned in the past, I'm not particularly fond of exposing IQueryable from the repository. I prefer to encapsulate querying logic into separate query objects, and these query objects can use linq under the covers. I like to ensure that queries have been executed at the repository boundary and there's no possible deferred loading weirdness going on :)
Regarding exposing system.linq types in the repository API: Even though these are in the BCL, I'd stay away from exposing them, although I think this is more acceptable on an 'application specific' repository as opposed to a repository defined in an external framework.
This is the repository I'm using in my current application:
public interface IRepository {
T[] FindAll<T>() where T : class;
T Fetch<T>(T example) where T : class;
T Query<T>(IQuery<T> query);
void Insert<T>(T item) where T : class;
void Delete<T>(T item) where T : class;
}
Note the lack of SubmitChanges. IMO including SubmitChanges on the repository breaks SRP - transaction/unit of work lifetime management should be handled externally. For example, in my current application I use ActionFilters to begin a unit of work at the start of an HTTP request and then submit changes at the end of the request.
Looking forward to your talk next week!
Jeremy
> I use ActionFilters to begin a unit of work at the start of an HTTP request and then submit changes at the end of the request.
Neato!
Why not have IRepository implement IQueryable? It expresses the same concept as GetAll() without having to invent a name :-)
Setting aside all knowledge of frameworks and technicalities, ask: is a repository something that is queryable?
I would argue that yes, in the abstract, a repository may be queried. Specific repositories may expose specific queries, but the *ability to be queried* is a core responsibility. IQueryable captures exactly that.
The NCommon project also provides a Repository which may be of interest - particularly it is fairly small and allows Linq.
@Jeremy Skinner
Playing the devil's advocate here, how would your action filters differ from HTTP modules ? Are you using those filters to implement to Open Session In View (OSIV) pattern ?
After a couple of years now of ORM experience I would now advocate not to return any ORM loaded entities outside of the Domain and instead return consumers (Web/Winform/WPF/Webservice) specific entities only, that means no use of OSIV and instead short Unit Of Works.
This architecture comes with a lot of benefits but at a high cost, the system will be littered with mappers at Domain Model boundaries.
@Mike
Maybe instead of showing how a Repository should look like I think you can talk about the driving factors for its design.
It's funny that for such a small problem area people can still argue for ages about it :)
@Daniel
The approach I'm taking is similar to OSIV, but not quite the same. I commit my UOW in OnActionExecuted, so the UOW is disposed before the view is rendered. I guess you could call it 'open session in controller' ;)
As I understand it, the purpose of OSIV is to allow for lazy loading in views. I don't like this for the same reason I don't like exposing IQueryable - it isn't obvious just where your database calls are going to occur. Instead, I tend to use eager loading at the repository boundary. So the purpose of my UnitOfWorkFilter is not to allow for lazy loading, but simply to provide implicit change tracking for the entire http request.
Perhaps you could you elaborate on why you prefer shorter Units of Work?
Good idea about discussing the driving factors behind repository design. Perhaps that's something Mike could talk about in his presentation :)
@Jeremy:
By shorter Unit Of Works (UOW) I mean that you use one only when you need to track changes that needs committing to the database.
That means View bound to View specific models (some call them the ViewModel, some simply DTOs) and only use a UOW when a UI action requires persisting to the Domain.
I haven't personally done this but I wonder if this design could help decoupling the UI from the Domain (if that sounds worth doing it).
Daniel, An excellent list. That's enough to keep me blogging for a month on repositories :)
I think part of the disagreements were having are about semantics. I'm starting to agree with the DDD guys that 'repository' is probably the wrong name a generic persistence store. How about IPersist'1 instead? If we accept that 'repository' is an invention of DDD gurus like Fowler and Evans, then we should try to keep to its original meaning. Jeremy makes a very good point (elsewhere) that unit testing extension methods can be problematic.
Jeremy, Very good point about SubmitChanges, I do agree that having a unit of work per request/action/view or whatever makes more sense and it shouldn't be the responsibility of the repository. That goes for transaction scope as well.
http://www.codeinsanity.com/2008/08/implementing-repository-and.html
Think you might like this article I found not long ago if you haven't already found it... It's still a little wet around the ears and i've yet to have a play but I like the idea of the specification pattern with the repository pattern and I especially like the ability to do this with lambda expressions.
This forces you to write methods/classes that encapsulate any queries made to a data store which will allow some form of unit testing (I hope) and it will force the programmer to think about what they are writing.
I don't like the idea of exposing IQueryable<T> from the repository as it does feel leaky and you will get the problem of certain queries not able to be converted to different ORM's.
Post a Comment