I've recently been asked to architect and build my first major Silverlight based application. The requirement is for an on-line accommodation booking service for a large multi-site educational institution. As a fully paid up member of the ORM mafia I really wanted to have the same persistence ignorance on the client that I enjoy on the server. The only way I could see to achieve this was building some kind of generic web service front end on top of my repository model along with a client side proxy that behaved in much the same way. It looked like a lot of work.
Enter ADO.NET Data Services. The first thing I'll say about it, is that the name is really crap. I can't see how this has anything remotely to do with ADO.NET. Fundamentally it's a combination of a REST style service over anything that provides an IQueryable implementation, plus client side proxies that expose an IQueryable API. Here's a diagram:

The Data Context can be any class that has a set of properties that return IQueryable<T> and that implements System.Data.Services.IUpdatable and System.Data.Services.IExpandProvider. The IQueryable<T> properties give the entities that are exposed by the REST API, IUpdatable supports (as you'd expect) posting updates back to the Data Context and IExpandProvider supports eagerly loading your object graph. The REST API has lazy load semantics by default, with all entity references being expressed as REST URLs.
It's very nicely thought out and easy to use. You simply create a new DataService<T> where T is your Data Context and the service auto-magically exposes your data as a RESTfull web service. I've been playing with the Northwind example. You just create a new Web Application in Visual Studio, add a "LINQ to SQL classes" item to your project and drag all the Northwind tables onto the LINQ-to-SQL designer. Next add an "ADO.NET Data Service" to the project then it's just a question of entering the name of the NorthwindDataContext class as the type parameter of the DataService:
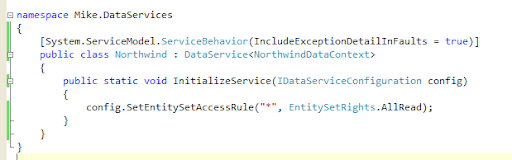
Note I've also added a ServiceBehaviour to show exception details in faults. Now when I hit F5 I get this error:
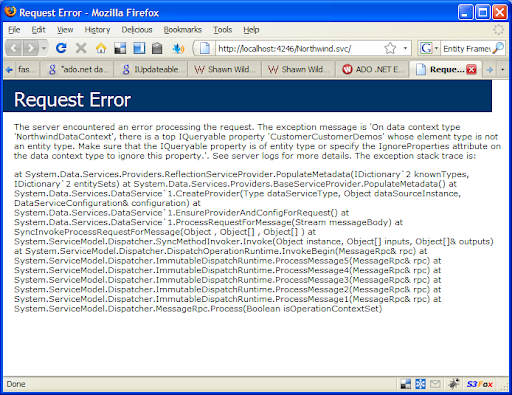
The way that ADO.NET Data Services works an entity's primary key is pretty simplistic. It just looks for properties that end with ID and gets confused by CustomerCustomerDemos. Shawn Wildermuth explains about this issue here. So I'll just remove everything from the designer except for tables with an obvious Id, and now I get this:
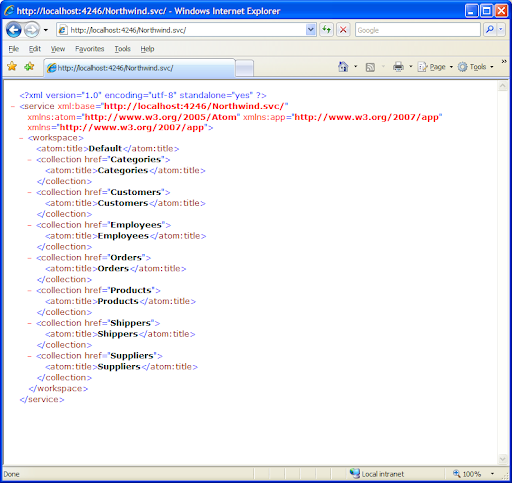
It's easy to explore the model by playing with the URL...
Currently only the much loved Entity Framework and LINQ to SQL provide a Data Context that you can use with this. David Hayden shows how to set up a LINQ to SQL project here. However, Shawn Wildermuth has been doing some great work exposing LINQ to NHibernate as a Data Service friendly Data Context. You can read about it here, here, here and here. His NHibernateContext is now part of the LINQ to NHibernate project. My project is using NHibernate as it's ORM, so I'll posting more about this soon.
You can download my sample using LINQ to SQL and Entity Framework here: